If your enterprise uses an application that Glean doesn’t natively support, you might wonder how to integrate that application with Glean. Maybe it’s an application developed in-house or a bespoke application provided by a third-party vendor, or a domain-specific application that Glean doesn’t natively support yet. Either way, it might seem like a challenge getting it integrated.
Not to worry—in this blog, we’ll guide you through some high-level decision-making regarding integration options.
Identifying integration types
For starters, Glean has two primary integration types: connectors and actions.
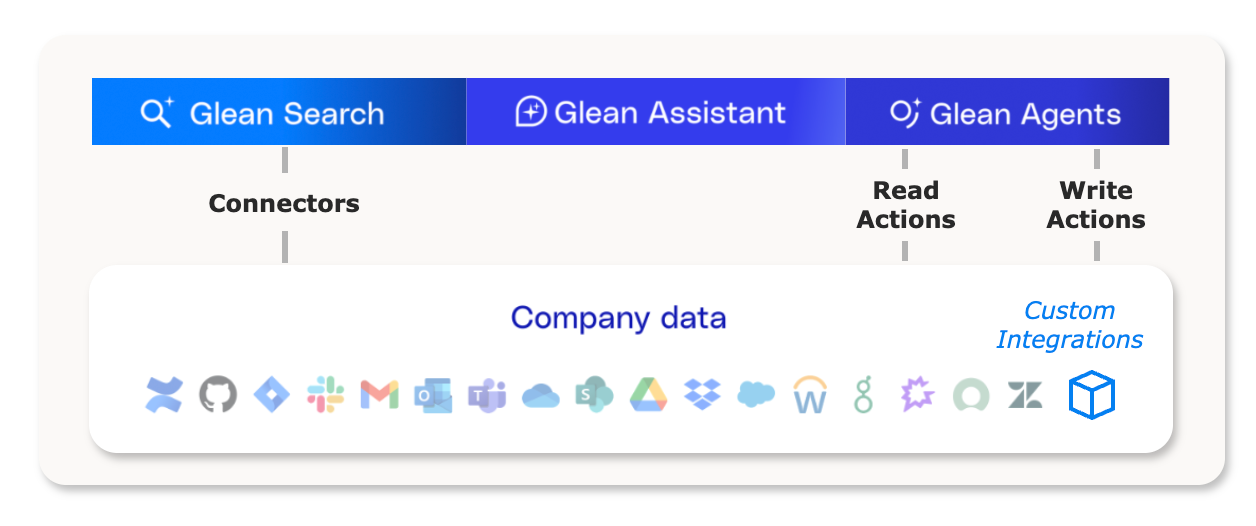
- Connectors sync content and permissions using application APIs. The Glean Platform organizes the data in an index to support a hybrid keyword-plus-semantic search engine. They work well for unstructured and semi-structured data.
- Actions execute operations using application APIs and run-time authentication. Read actions fetch data; they work well with structured data or when a connector cannot keep data up-to-date. Write actions push data on behalf of the user.
Choosing the integration type is most often dependent on two factors. The primary factor is how the data is organized. The secondary factor is the use case(s). The next section describes the three different data organizations. Within each data organization type, the impact of use cases on the integration choices is discussed.
The right approach for each data organization
Most enterprise applications are characterized by a primary data organization that defines the rule-of-thumb integration type: unstructured, semi-structured, or structured. Based on each data organization type, you’ll want to consider connectors or actions as your primary method of integration—or sometimes a combination of both.
- Unstructured data is generally how we communicate with each other in documents, PDFs, emails, chat, and other mediums. Common enterprise applications that focus on unstructured data include Google Drive, O365, Slack, Outlook, Gmail, Confluence, and Teams. Indexing unstructured content with keyword lookup, semantic indexing, and integration with Glean’s enterprise graph improves the system’s ability to surface the best context, so you should almost always choose a custom connector as your integration approach. You might want to consider actions for live fetch of documents if real-time access is important for your use cases.
- Semi-structured data will often have natural language data with an organizational structure. Some examples include survey results and forms. More complex applications like Salesforce and Jira have semi-structured frontend systems with structured backend systems. If your focus for the integration is to mirror how a user interacts on the frontend, then consider that application as semi-structured. If the use case is natural-language driven, you should default to a custom connector, for the same reasons listed above. You should default to actions if the use case is database-query driven, because structured data doesn’t get surfaced in search as well. You may also consider implementing both, which Glean chose to do with some of its native connectors like Salesforce and Jira.
- Structured data is intended for machines to work with. It is consistently organized with schema, like an SQL database schema or the Salesforce database schema. Data warehouses, databases, ticketing systems, CRMs, and HRISs are applications that use structured data. In most cases, structured data does not belong in a search index, as it adds unnecessary noise to the system for keyword lookup and has limited context for semantic lookup. For structured data, you should default to actions in almost all cases. The exception would be if you are indexing specific frontend views of the data, in which case your use case is more similar to unstructured or semi-structured data. Consider combining your actions with a custom connector to index metadata or semantic data. This dual approach can give tools like Glean a powerful mechanism to perform plans that first find the right database or table and then automatically create queries to access the right underlying data.
Depending on your data organization, your path to integrating different applications and data sources will differ—hopefully, this blog provided you with some clarity about how to approach the process.


